
Issue #10: ML Lessons at Booking.com. AI meets Physics. Insights from Google Medical AI.


Welcome to the 10th issue of the ML Ops newsletter. We are excited to have hit the two-digit mark in terms of the number of issues we have published so far. Only 90 more to go until the next milestone. 💪
Now, for the topics in this issue, we begin with a paper with lessons from 150+ successful ML models in production, discuss ideas at the intersection of AI and Physics and look at a review of a Medical AI case study from Google. We also share details on some events and other resources.
Thank you for subscribing, and if you find this newsletter interesting, forward this to your friends and support this project ❤️
Paper | 150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com

This is a wonderful paper by the team at Booking.com. Booking.com are one of the largest online travel agent website catering to millions of guests and accommodation providers across the world. They describe their motivation for this paper perfectly:
While most of the Machine Learning literature focuses on the algorithmic or mathematical aspects of the field, not much has been published about how Machine Learning can deliver meaningful impact in an industrial environment where commercial gains are paramount.
For folks who are struggling to deliver value with ML models at their companies, take heart by Booking.com’s experience:
We found that driving true business impact is amazingly hard, plus it is difficult to isolate and understand the connection between efforts on modeling and the observed impact.
Let’s break down some of their lessons by phases of the development process.
Inception + Design
ML models can have various levels of specificity - they can be extremely specialized (providing recommendations on a very specific page) or they can be very general that almost act as a “semantic layer” for the product team (such as how flexible a user wrt final destination of their trip). In their analysis, they found that: “on average each semantic model generated twice as many use cases as the specialized ones.”
We have seen this in our own experience - training generic NER models and using their predictions can be useful in other text classification problems.
Modeling
We loved this section. Check out what they have to say about model performance and business metrics and the image that follows:
In Booking.com we are very much concerned with the value a model brings to our customers and our business. Such value is estimated through Randomized Controlled Trials (RCTs) and specific business metrics like conversion, customer service tickets or cancellations. A very interesting finding is that increasing the performance of a model, does not necessarily translates to a gain in value.

There could be many reasons for this -- business metrics might already be saturated (no further improvements in booking rate can realistically be achieved), labels for training data might not directly map to business value (for example clicks might not be a good proxy for value), etc.
Deployment
When they introduce synthetic latency, they find a strong correlation between prediction latency and conversion rate.

This leads to many strategies for making predictions faster: models distributed across a cluster, faster linear models, sparse models and precomputation and caching where possible.
Monitoring
Since we don’t have access to true labels (or if labels are delayed), metrics such as precision and recall are inappropriate. They recommend monitoring the distributions of predictions and looking at their histograms.
Conclusion
With 150 successful applications of ML on their e-commerce platform, their main conclusion is that an iterative, hypothesis-driven process that is deeply integrated with other disciplines was fundamental.
Finally, here’s a short video from them about this paper:
Upcoming Events
ML Happy Hour

We’re excited to share that we are going to be speaking with the team at Superwise.ai at an ML Happy Hour this week. We will talk about MLOps and why you should monitor your ML models in production. Sign up here to join us on Jan 28!
TWIMLcon

We have been attending talks and meeting people (virtually) at TWIMLcon throughout last week and are looking forward to all that is to come this week. If you’re still looking to attend the conference, you can use the following discount code - MLOPSROUNDUP - to get a 20% discount. Send us a message if you’re attending as well!
AI & Physics: Intelligible Intelligence
Max Tegmark, the co-founder of the Future of Life Institute and a professor at MIT, is a leading researcher on AI safety and explainability. In a recent podcast with Lex Friedman, he discussed his views on these topics. We share a few highlights here and certainly recommend listening to the entire podcast.
AI meets Physics: Much of the innovation in deep learning and AI over the last decade has come from large tech companies and AI today is primarily an engineering discipline focussed on building products and solving problems. Physics, on the other hand, is focussed on explaining the natural world. In the coming years, we will see explainability research in AI resemble a lot more like Physics.
AI safety: The reason we should pay attention to AI safety is not due to a fear of robots becoming “evil” and destroying the world but because of misplaced trust - we are building more complex and large models whose decisions increasingly have an impact outside the digital sandbox. As an example, Max brought up Knight Capital, which deployed automated trading software that cost the firm $440 million dollars in a few hours.
“It took 17 years of dedicated work to build Knight Capital Group into one of the leading trading houses on Wall Street. And it all nearly ended in less than one hour.”
Goal alignment: How do we encode the real-world impact (good or bad) of an AI’s predictions in the objective function when training models, to make sure the goals on the second and third-order are aligned? This is a largely unsolved problem.
Our take
In Max Tegmark’s view, the central problem in AI safety is to understand models so well as to be able to make provable claims about things that it will always do/never do. We believe AI safety is still in its infancy and largely in the domain of research. Should the problem formulation be to make provable claims about a model? Should it be to mitigate downsides? Should it be to eliminate bias? These are open questions in our view, and we look forward to the tools and techniques that are developed as part of AI safety research in the coming years.
Google’s Medical AI was accurate in the lab. Real life was a different story
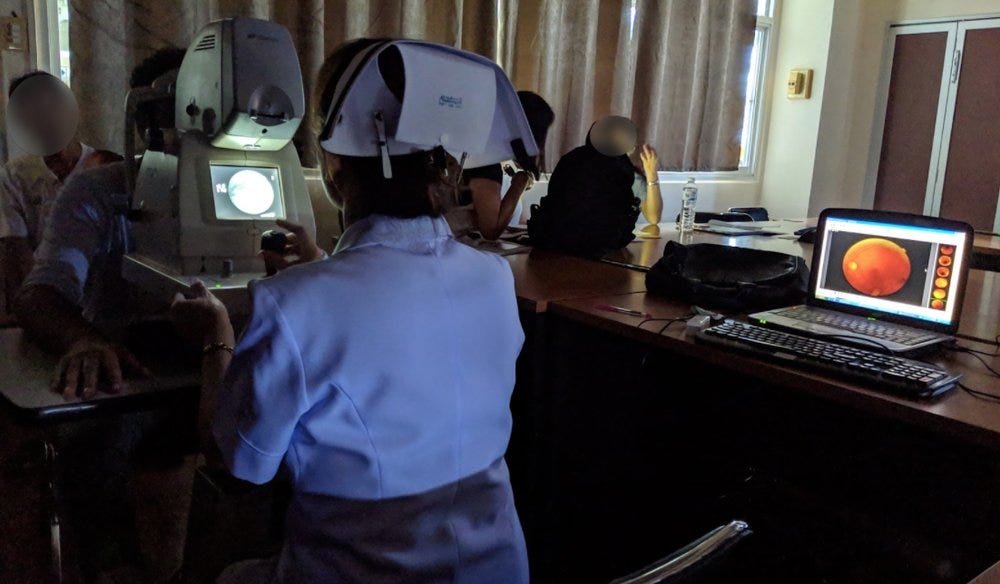
We love to cover stories that document the “ML in a lab → ML in the real world” journey. This week, we share an article on this theme in the domain of medicine. This study, published in 2020 by Google Health, reveals important insights about the importance of tailoring the entire human-in-loop decision workflow (not just the model) when it comes to deploying medical AI advances in the real world.
Google deployed a cloud-based AI tool to detect diabetic retinopathy across 11 clinics in Thailand. Nurses would take pictures of photos of patients’ eyes and send it to this tool to get the models’ prediction. Compared to the previous workflow (where the photos were sent to specialist doctors) the new workflow was expected to reduce the turnaround time from weeks to minutes. As noted in the article, the team found out a bunch of issues that can arise from real-world messiness, even if the model has high accuracy:
“When it worked well, the AI did speed things up. But it sometimes failed to give a result at all. Like most image recognition systems, the deep-learning model had been trained on high-quality scans; to ensure accuracy, it was designed to reject images that fell below a certain threshold of quality. With nurses scanning dozens of patients an hour and often taking the photos in poor lighting conditions, more than a fifth of the images were rejected.”
Additionally, there were learnings around integrating models in the rest of the workflow. For example, in this case study:
“Patients whose images were kicked out of the system were told they would have to visit a specialist at another clinic on another day.”
Our take
Firstly, we appreciate Google’s transparency here. Learnings and insights shared by their team, in seeing their own technology receive mixed results in the field, will be valuable for any reader. Setting the issues around training/test data mismatch and data drifts (which we have highlighted in past issues) aside, what was new for us were the complexities of human interface issues of deploying AI. As we build systems that leverage state of the art AI techniques, it is important for us to think through these issues in order to realize real-world impact.
Fun | Risitas Learns about MLOps
We can’t recommend watching this video enough -- we have watched it multiple times and it always makes us laugh. Thanks for the super fun content, Ariel Biller!
From our Readers

Vik Chaudhry shared an interesting library with us: Pycaret. This library provides a wrapper around libraries like scikit-learn, xgboost, etc so that with a few lines of code, you can train many different models on your training data to speed up some of your workflows. It also includes an integration with MLFlow so results of the experiments can be logged against your MLFlow server. If you have used this in the past, drop us a note and tell us about your experience!
Thanks
Thanks for making it to the end of the newsletter! This has been curated by Nihit Desai and Rishabh Bhargava. This is only Day 1 for MLOps and this newsletter and we would love to hear your thoughts and feedback. If you have suggestions for what we should be covering in this newsletter, tweet us @mlopsroundup (open to DMs as well) or email us at mlmonitoringnews@gmail.com