
Issue #16: EU AI regulations. Data-centric AI. Scale Transform 2021. Explainability via Memorization.


Welcome to the 16th issue of the MLOps newsletter.
In this issue, we begin with some news out of the EU on AI regulation, followed by a fascinating paper on explainability using nearest neighbours. Next, we discuss a few talks from Scale’s Transform conference and deep dive into an insightful Andrew Ng talk on taking a data-centric view of AI.
Thank you for subscribing. If you find this newsletter interesting, tell a few friends and support this project ❤️
The Verge | The EU is considering a ban on AI for mass surveillance and social credit scores

What happened?
From the Verge:
“The European Union is considering banning the use of artificial intelligence for a number of purposes, including mass surveillance and social credit scores. This is according to a leaked proposal that is circulating online…”
This would lead to certain use cases being regulated (similar to privacy rights under GDPR) by member states of the EU, and if companies sell prohibited software, they “could be fined up to 4 percent of their global revenue” (and not European revenue). Here is the draft of the regulation, if you’re interested.
What do the regulations include?
A ban on AI for “indiscriminate surveillance,” including systems that directly track individuals in physical environments or aggregate data from other sources
A ban on AI systems that create social credit scores, which means judging someone’s trustworthiness based on social behaviour or predicted personality traits
Special authorization for using “remote biometric identification systems” like facial recognition in public spaces
The creation of a “European Artificial Intelligence Board,” consisting of representatives from every nation-state, to help the commission decide which AI systems count as “high-risk” and to recommend changes to prohibitions
Reactions
As mentioned in the Verge article, Daniel Leufer, Europe policy analyst at Access Now says:
“The descriptions of AI systems to be prohibited are vague, and full of language that is unclear and would create serious room for loopholes”.
From Twitter:


Our Take
We understand how difficult it is to write good regulation, especially in domains that involve new technologies, such as artificial intelligence. And while it is critical that AI/ML companies are regulated appropriately to protect consumers of AI software from harm, we do believe that it needs to be done carefully and thoughtfully. Poorly written regulation can itself have many ill-effects: difficult to enforce consistently, loopholes, push companies away from deploying in the EU, making the market anti-competitive for smaller companies, etc.
We will be following this closely to see what changes are made to this draft proposal, with a potential announcement on April 21st.
Andrew Ng Talk | MLOps: From Model-centric to Data-centric AI
Andrew Ng probably needs no introduction for the readers of this newsletter. He recently gave a talk about the importance of striking the right balance between data and modelling improvements in real-world ML applications. It is an hour long and filled with practical insights and learnings and we recommend watching it fully. Overall, the message and theme of this talk is music to our ears and one of our motivations for writing this newsletter.
Model v/s data-centric approaches to AI

Much of the high visibility work, especially in research and academia, happens in the realm of improving model architectures, learning schemes etc whereas the benchmark training and test sets are standardized and static (think ImageNet, MNIST, SNLI dataset etc). This is the opposite of most real-world settings where the data is messy, noisy, ever-changing.
In Ng’s view, this has ensured we’ve had great progress in the realm of model-centric AI but we don’t place nearly enough importance on data collections & quality in most applications.
How is MLOps different from DevOps?

Real-world AI systems (Software 2.0) are a combination of Software and Data.
In Andrew Ng’s view, the rising and nascent field of MLOps can play a role in AI systems that’s equivalent to DevOps in the traditional software world.
Unlike software 1.0 which is mostly feed-forward (build → package → deploy), AI systems have feedback loops which means that MLOps plays a critical role in establishing best practices and processes around establishing these feedback loops from post-deployment back to model training and data collection.
MLOps as a way to systematize best processes around data quality
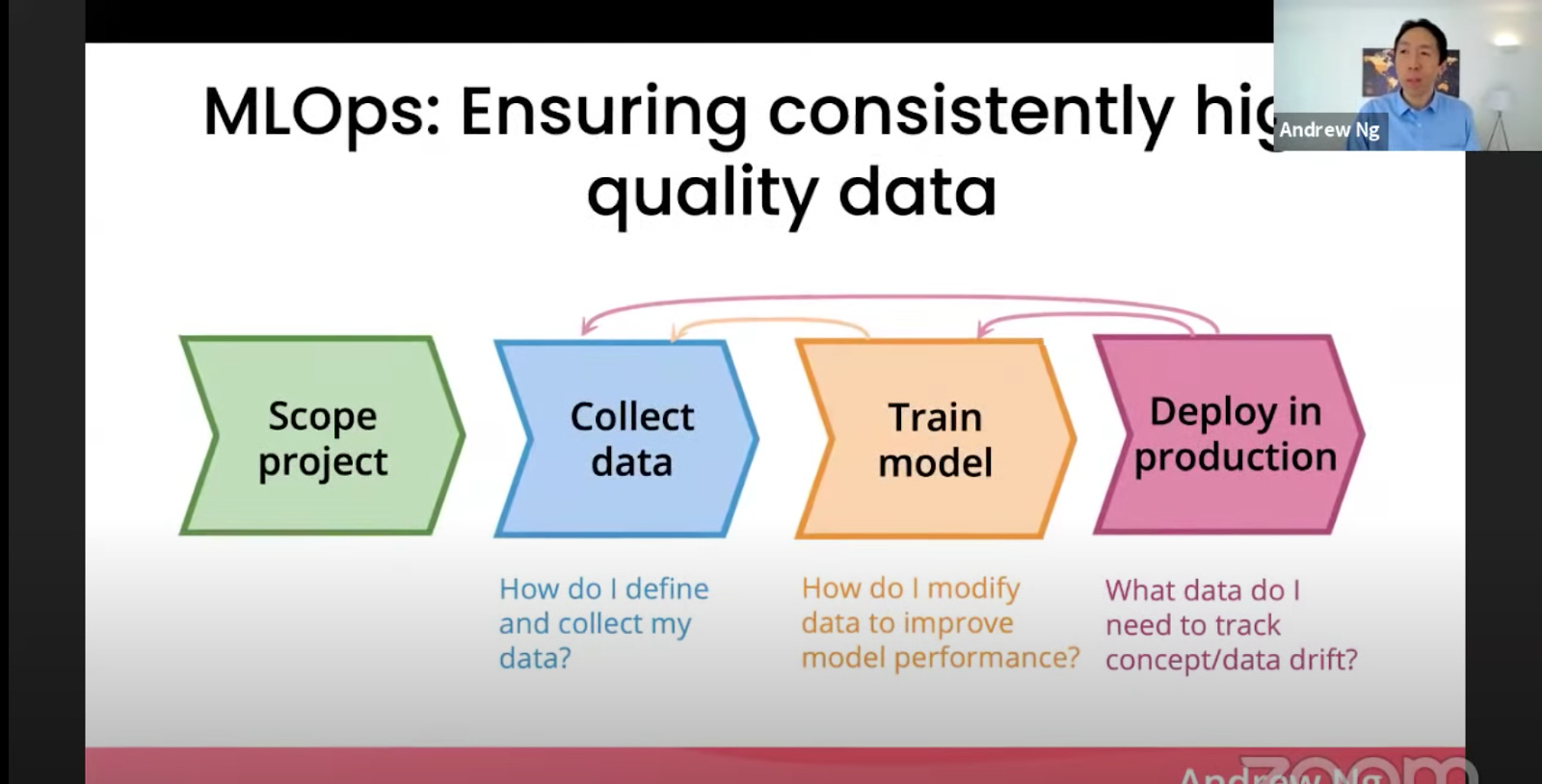
In Andrew Ng’s view, the biggest value an MLOps team can provide is to ensure consistently high-quality training data.
In this sense, MLOps plays an important role across the model development and deployment lifecycle: how to get enough training data? How to ensure label consistency? How to clean and transform data to improve model performance? How to track concept and data drifts in deployed models?
James Le | Learnings from Scale Transform 2021


James Le always does an incredible job of capturing notes from the conferences that he attends (last year we had included his post on the Toronto ML Summit), and his latest post from Transform, Scale’s conference doesn’t disappoint.
We recommend reading the entire post, but here we wanted to cover a couple of the talks that were interesting from an MLOps perspective.
AI at Facebook Scale
This was a talk by Srinivas Narayanan, who is the Director, Applied Research at Facebook AI. The talk goes into a few different challenges faced by a company at Facebook’s scale.
Data Challenge: Scaling Training Data

One of the biggest challenges in building AI systems is getting the right and sufficient training data. Getting labeled data for supervised learning can be difficult, expensive, and in some cases, impossible. Facebook approaches this by focusing on techniques beyond supervised learning.
For example, at Instagram, FB was able to train an object-classification system using 3.5B images along with the hashtags there were shared with, which is a technique called weak supervision. This allowed them to leverage a much larger volume of training data, leading to state-of-the-art results.
Similarly, they were able to use self-supervision (where the system learns to fill in the blanks for inputs with missing pieces) to train cross-lingual language models and audio models. Again, with a smaller amount of labelled data, they are able to achieve good results.
Tooling Challenge: Building the AI Platforms

As can be seen in the image, Facebook has built out a rich roster of internal tooling to support their AI efforts. As James writes:
On the left, you’ll see tools for preparing data in the right format.
In the middle, you’ll see the pieces for building and training models — going bottom up all the way from hardware, whether it’s CPUs or GPU’s. These include frameworks like PyTorch that ease the model building environment, libraries that are specific to each domain, and the models that are used in products.
And on the right, once you have the trained models, you have the right tools and systems for deploying them in production, whether it’s in a data center or locally on the device.
And to make the research to production flow smooth, Facebook invested heavily in PyTorch as a single framework.
Bias Challenge: Creating AI Responsibly

As James writes:
Not introducing or amplifying bias and creating unfair systems is a challenge because it’s not as simple as using the right tools. Fairness is a process. At each step of the implementation process, there is a risk of bias creeping in — in data and labels, in algorithms, in the predictions, and in the resulting actions based on those predictions.
At each step, Facebook attempts to surface the fairness risks, resolve questions and document the decisions that were made.
Applied ML at Doordash
Andy Fang, co-founder and CTO at DoorDash discussed a couple of case studies of how DoorDash uses AI to improve its business. The one that we’ll cover is their process for creating a rich item taxonomy.

DoorDash has tens of millions of items across all its restaurants and tens of thousands of new items are added every day. These have to be sorted and categorized so that users can quickly understand the offerings on the DoorDash platform, and make the best (ie tasty) decisions for themselves.
DoorDash managed to achieve this with a rich taxonomy, models that categorize each item into this taxonomy and a human-in-the-loop system that reduces annotation costs while allowing them to grow their taxonomy efficiently.
There are three critical rules for defining annotation tags:
Make sure that there are different levels of item tagging specificity that don’t overlap. Let’s say for coffee, you can say it’s a drink, you can say it’s non-alcoholic, or you can say it’s caffeinated. Those are three separate labels that don’t overlap and categorization with each other.
Allow annotators to pick “others” as an option at each level. Having “others” is a great catch-all option that allows DoorDash to process items tagged in this bucket to see further how they can add new tags to enrich their taxonomy.
Make tags as objective as possible. They want to avoid popular or convenient tags — things that would require subjectivity for an annotator to determine.
Also, when defining tasks for human annotators, it is important for the tasks to be high-precision and high-throughput.
High precision is critical for accurate tags, while high throughput is critical to ensure that the human tasks are cost-efficient.
DoorDash’s taxonomy + simple binary/multiple-choice questions help them achieve high precision for their models with less experienced annotators and less detailed instructions. Finally, a separate QA loop on the annotations maintains high annotation quality.
Paper | Explaining and Improving Model Behavior with k Nearest Neighbor
Representations

This recent paper from Salesforce Research explores the idea of improving model explainability by searching for similar examples from the model’s training data.
Highlights
The paper proposes using k-nearest neighbors in some representation space to identify training examples that are most similar to the example that the model is currently producing a prediction for. These examples from the training set (and the labels associated with them) can be interpreted as the ones most responsible for the model’s prediction.
In addition, the paper presents a generic implementation of the space in which k-NN should be computed for this application: the deep learned model’s output hidden layer representation. This intuitively makes sense in that this representation is learned specifically for the training task, and in this way, the meaning of “nearness” is learned contextually to the downstream task for which the model is doing inference.
As an additional benefit, the paper shows that oftentimes looking at nearest neighbors of misclassified examples can surface label noise (incorrectly labelled examples) in the training data.
Our take
Explainability is a problem that has received a lot of attention and visibility in the last few years, both by researchers and ML practitioners alike. And for good reason: increasingly we’re seeing applications of machine learning outside of their digital-only sandboxes and out into the physical world (think self-driving cars, healthcare, autonomous drones). The technique presented in this paper appeals a lot to us - it is conceptually simple to understand and offers a way to explain model predictions by reasoning by analogy. A couple of open questions/interesting directions to explore:
Can k-NN based explanation techniques be extended to tasks beyond classification, for instance, question answering, textual entailment or machine translation?
Can the representations learned for this kNN search have other applications in the domain of MLOps and monitoring? For instance, measuring data drift?
Fun | Machine Learning Pipelines are hard


Thanks
Thanks for making it to the end of the newsletter! This has been curated by Nihit Desai and Rishabh Bhargava. If you have suggestions for what we should be covering in this newsletter, tweet us @mlopsroundup (open to DMs as well) or email us at mlmonitoringnews@gmail.com.