
Issue #17: FTC Guidance on AI. Feature Store vs Data Warehouse. #datalift. Unsupervised Dataset Generation.


Welcome to the 17th issue of the MLOps newsletter.
In this issue, we cover some recent developments on AI regulations, discuss the similarities and differences between data warehouses and feature stores, and share our thoughts on a recent paper about dataset generation using language models.
Thank you for subscribing. If you find this newsletter interesting, tell a few friends and support this project ❤️
A Quick Update on the EU AI Regulations

In our last issue, we had discussed the AI regulations that the EU had been considering. This week, the EU Commission released its proposed AI Framework to address the risks associated with AI. It still needs to be adopted by the European Parliament and member states, but it is likely to pass through successfully. However, if this follows a path similar to GDPR, it will be a few years before it is enforceable (the earliest estimate is the second half of 2024).
From Reuters, European tech chief Margrethe Vestager:
"On artificial intelligence, trust is a must, not a nice to have. With these landmark rules, the EU is spearheading the development of new global norms to make sure AI can be trusted"
Our very short take
AI risks are very real and need good regulation. That being said, we do need to be careful about poorly written regulation, and we hope that there will be significant discussion in the next few months and years about AI risks.
FTC | Aiming for truth, fairness, and equity in your company’s use of AI

The FTC recently provided guidance to companies on building AI applications with an aim for truth, fairness, and equity, that we wanted to share with our readers. This guidance comes almost a year after a previous FTC recommendation about the use of AI technologies and shows perhaps that the topic continues to be a high priority.
Existing laws
The guidance includes a reminder on the three laws that are important to this conversation:
(1) Section 5 of the FTC Act. The FTC Act prohibits unfair or deceptive practices. That would include the sale or use of – for example – racially biased algorithms.
(2) Fair Credit Reporting Act. The FCRA comes into play in certain circumstances where an algorithm is used to deny people employment, housing, credit, insurance, or other benefits.
(3) Equal Credit Opportunity Act. The ECOA makes it illegal for a company to use a biased algorithm that results in credit discrimination on the basis of race, color, religion, national origin, sex, marital status, age, or because a person receives public assistance.
Recommendations
In the guidance, the FTC also issued recommendations for companies to follow when building AI applications. For ML researchers and practitioners, these might not be very new but it is great to see these practices and recommendations get more visibility. You can check out the full list of recommendations on FTC’s website but we share our thoughts below:
Focus on foundations: The guidance focuses on the importance of starting with datasets that are unbiased and representative of the world in which the models will operate
If a data set is missing information from particular populations, using that data to build an AI model may yield results that are unfair or inequitable to legally protected groups.
Focus on transparency and practices: The guidance focuses on the importance of transparency in how datasets and models are used, including third-party audits, unambiguous terms of service to inform users, and not making exaggerated claims about the model’s real-world performance.
As your company develops and uses AI, think about ways to embrace transparency and independence … by conducting and publishing the results of independent audits, and by opening your data or source code to outside inspection.
Cited examples: One thing that struck us while reading the article was the citations of bias in AI, and actions against these violations in the past: racial bias in the healthcare algorithms, a complaint against Facebook, and recent action against Bronx Honda car dealership. To us, these examples and the strong language associated with them, indicate that FTC is serious about enforcing these laws in the context of AI applications.
Reactions
This series of tweets by University of Washington School of Law professor Ryan Calo is a good read.


Medium | Feature Stores vs Data Warehouse
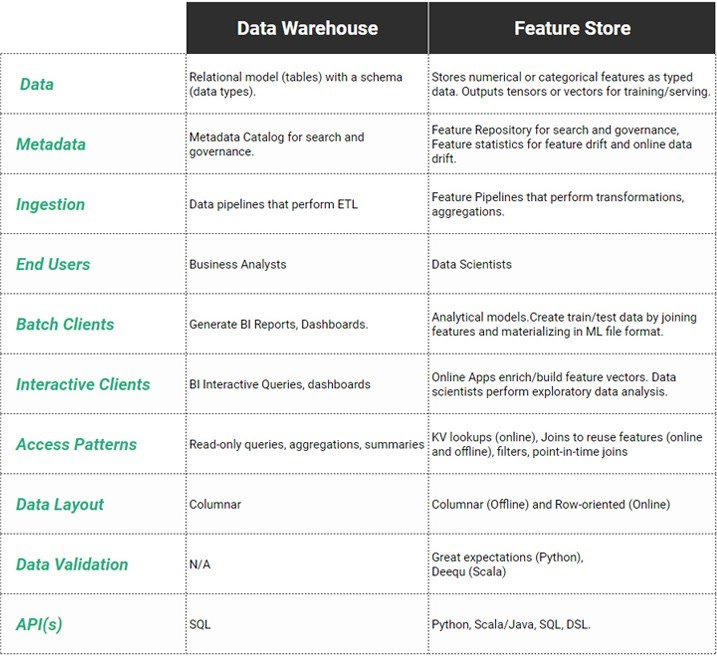
In a recent post, Jim Dowling highlights the similarities and differences between data warehouses and feature stores. The feature store is a data warehouse of features, used for training and inference of ML models. Both, data warehouse and feature store, are a central store of data and both have pipelines to ingest data from one or more sources. However, as noted in the post, there are some important differences in terms of architecture and use-cases.
Dual Use-Cases of Feature Stores
Unlike data warehouses, which are used typically for offline batch processing of data for gathering insights, reporting, etc, feature stores support a dual use-case:
Offline use-case (column-oriented) for training models and offline batch inference
Online use-cases (row-oriented) for online inference i.e. individual predictions.
Data validation in Feature Stores
A data warehouse stores data in tables along with predefined schemas and column constraints. By contrast, feature stores typically have more relaxed constraints and at the same time, they can store more abstract data (e.g. an array of floating-point values as an input feature vector of a model). For feature stores, it is best to do data validation and quality checks before ingestion. The article mentions example data validation tools like Great Expectations, which we have covered earlier in our newsletter as well.
As model training is very sensitive to bad data (null values, outliers cause numerical instability, missing values), feature data should be validated before ingestion
Feature Statistics Monitoring
As we have covered previously in our newsletter, data and feature drifts are important to monitor for real-world ML applications. Many feature stores can facilitate comparisons of online traffic against the training or validation sets for the detection of such drifts.
Event | #datalift No 5 - Productionize data analytics and machine learning

#datalift is an initiative from the AI Guild which brings together a community of AI practitioners, and business leaders to help bridge the gap between proof-of-concept and productionization. They’re hosting an event on May 28 with many interesting speakers and opportunities to network with folks who are interested in ML deployments. We’ll be attending and hope to see you there!
Paper | Generating Datasets with Pretrained Language Models

What’s the problem?
One of the major challenges in machine learning (especially when working with unstructured data like text, images, videos) is getting good representations for data. In NLP, this has typically meant embeddings, which were popularised by the Word2Vec paper from 2013. While there have been many innovations (such as large pre-trained language models like GPT-3) that have changed the NLP landscape over the last few years, generating good sentence-level embeddings for downstream tasks remains difficult.
As the authors say:
To obtain high-quality sentence embeddings from pretrained language models (PLMs), they must either be augmented with additional pretraining objectives or finetuned on a large set of labeled text pairs. While the latter approach typically outperforms the former, it requires great human effort to generate suitable datasets of sufficient size.
How do they solve this problem?
This paper introduces a method of leveraging pre-trained language models to:
generate entire datasets of labeled text pairs from scratch, which can then be used for regular finetuning of much smaller models.
This is done by prompting the language model (LM) in a very specific way (we’ll let you read the paper for full details) and generating tokens until full sentences have been produced. For example, as seen in the image above, the input could be the LM was the Task + Sentence 1, with Sentence 2 being the output.
This is neat because the LM is producing example pairs of sentences in a completely unsupervised fashion, and the sentences are going to be fairly fine-tuned to your dataset (if Sentence 1 is from your dataset) while Sentence 2 is produced using the knowledge of the LM.
What does this mean?
While we won’t focus on the results from this paper too much, we believe that this is an interesting direction for the future. Companies are often dealing with large amounts of unlabeled data where human labeling would be expensive. If large LMs can somehow be leveraged to create datasets or provide labels with reduced human intervention, we could radically speed up the time-to-production for many projects.
Crossing the Deep Learning Chasm: Why the prototype to production journey is hard

We came across this series of tweets by François Chollet, creator of Keras, about why the prototype to productionization journey for deep learning applications is hard.
This struck a chord with us:
Every app demo based on GPT-3 follows this pattern. You can build the demo in a weekend, but if you invest $20M and 3 years fleshing out the app, it's unlikely it will still be using GPT-3 at all, and it may ever meet customer requirements
Thanks
Thanks for making it to the end of the newsletter! This has been curated by Nihit Desai and Rishabh Bhargava. If you have suggestions for what we should be covering in this newsletter, tweet us @mlopsroundup (open to DMs as well) or email us at mlmonitoringnews@gmail.com
Thanks again, and if you like what we are doing please tell your friends and colleagues to spread the word.