
Issue #25: Tesla AI Day. Feature Stores. NIST on AI bias. Model monitoring tips. AI and COVID.



Welcome to the 25th issue of the MLOps newsletter.
In this issue, we cover Tesla AI Day, a short paper about gaps in feature stores, updates about the NIST proposal to reduce bias in AI, tips on ML monitoring, and a tech review about the challenges of deploying AI tools for diagnosing COVID.
Thank you for subscribing. If you find this newsletter interesting, tell a few friends and support this project ❤️
Tesla | AI Day
We’ve covered updates about Tesla’s AI for self-driving cars in a prior edition of the newsletter. Tesla recently held an AI Day event to share its research and innovations across the stack for solving self-driving and the general real-world robotics perception & planning problem. It was a fascinating event and highlighted the scope and scale of Tesla’s AI efforts. We recommend watching it in its entirety. A brief summary of major innovations presented:
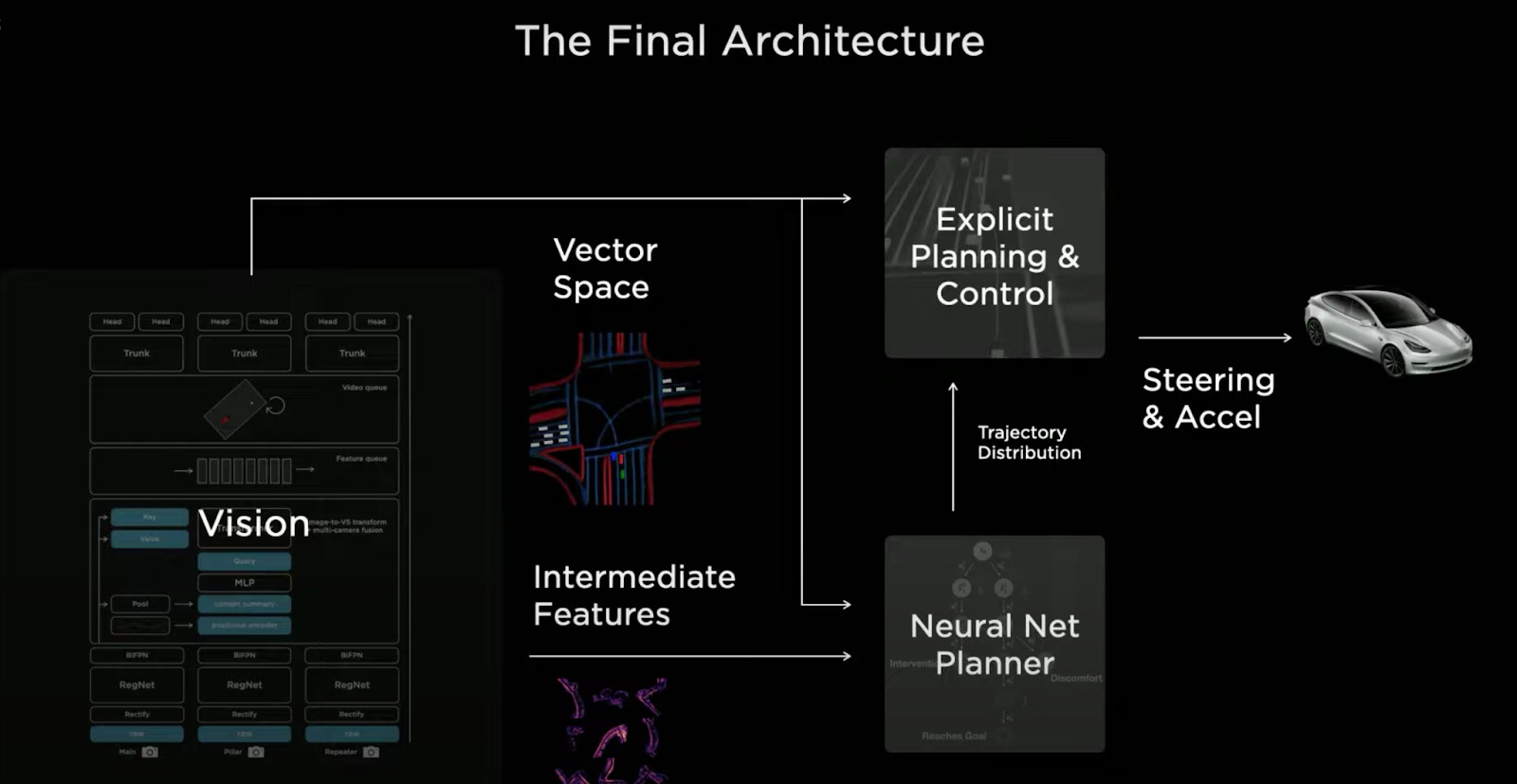
Network Architecture for Perception & Planning
Andrej Karpathy gave an overview of how deep learning models for perception have evolved over the last four years, starting from residual nets for lane-keeping to a fairly complex multi-task architecture trained to predict in the vector space (as opposed to static images)
Fusion of sensor data across all 8 car cameras and training the network to do the final prediction on the joint data. This brought a step function improvement compared to the earlier (arguably more straightforward) approach of making predictions on streams from each camera and then combining the predictions.
Perception on 4D video for modeling time progression (e.g. which objects are moving and which ones are stationary; what is the speed and trajectory of moving objects)
Tesla has started using neural networks not just for perception but also to improve the efficiency of searching through the action space for better planning and control.
Data Labeling & Augmentation
Annotating in the vector space means you annotate once, simultaneously creating labels for streams from all 8 input cameras across many timestamps.
Autolabeling is used to massively scale up the size of labeled data that the neural net can learn from. The details of how autolabeling is done (by leveraging video clips across different cars in the same physical location) are shared in this part of the talk.
Tesla leverages simulations for constructing training data for rare edge cases that are very unlikely in the real world.
Interesting note: Tesla hires >1000 human annotators in-house to work full-time on just data labeling tasks.
Dojo
Dojo is Tesla’s next-generation chip & data center architecture for fast training of large neural networks. It is still under development and expected to be rolled out next year.
The “exapod” setup, which brings together 3000 of these D1 chips, should enable 1.1 exaflops of configurable-FP8 compute.
From an ML engineer’s point of view, training on Dojo would involve just a one-line change to the code which makes it super easy to switch over.
Paper | Managing ML Pipelines: Feature Stores and the Coming Wave of Embedding Ecosystems

This is a short paper that discusses one of the shortcomings of today’s conception of feature stores -- that of dealing with embeddings as features, given that feature stores have typically been built for tabular data.
What is a Feature Store?
Feature Stores provide a centralized repository of reusable features during ML training and inference (you can also read our discussion here, here, and here). Features can be constructed using tabular data or stream data and are saved for training and serving time:
Users provide simple definitional metadata, e.g., the feature update cadence and a definition SQL query, and upload the definition to the FS. When the underlying data changes, the FS orchestrates the updates to the features based on the user-defined cadence.
For streaming features, users provide aggregation functions that are applied on the raw streaming features. The aggregated features are persisted to the online store and logged to the offline store…
Once a model is deployed, features need to be continuously provided to deployed models even as the feature data is updated over time. To provide low latency feature serving, FSs are typically a dual datastore: one for offline training (e.g., SQL warehouse) and for online serving (e.g., in-memory DBMS).
Where’s the gap?
Many ML systems today rely on embeddings that are derived from raw data (see examples from Twitter and Doordash). These embeddings are learned in a self-supervised manner; there are no labels and traditional metrics for data quality don’t apply here. These embeddings also need to be saved for training and inference time, and the dual datastores might not be an ideal fit for such embeddings. Finally, monitoring and detecting drifts with embeddings is a very different challenge compared to tabular data.
Solutions
In the past, we have covered vector databases (such as the Google Vertex Matching Engine covered here). These datastores are optimized for storage, retrieval, and search over embeddings and are a more natural fit for embeddings.
We are excited to see new technologies develop in this space to address the varieties of data types used by the ML community!
NIST Proposal: Reducing Risk of Bias in AI
Potential bias in machine learning models is a well-recognized problem in academia and industry today. In an effort to counter this, the National Institute of Standards and Technology (NIST) is advancing a proposal to identify and reduce the downstream risk of bias in AI.
The draft proposal is shared in NIST Special Publication 1270. The approach proposed in this report consists of three distinct stages, and inputs from accompanying stakeholders at each stage:
1. PRE-DESIGN: where the technology is devised, defined and elaborated
2. DESIGN AND DEVELOPMENT: where the technology is constructed
3. DEPLOYMENT: where technology is used by, or applied to, various individuals or groups.
NIST is accepting comments on the document until Sept. 10, 2021. Authors seek to use these responses to help shape the agenda of collaborative virtual events in the coming months. Comments can be submitted by downloading and completing this template form and sending it to ai-bias@list.nist.gov
Nubank Blog | ML Model Monitoring – 9 Tips From the Trenches

We always enjoy reading articles from ML teams in industry -- their lessons are hard-won and extremely applicable. This week we cover tips on ML monitoring from the Latin American company Nubank (now the largest digital bank in the world by number of customers: 40 million).
Why ML Monitoring?
“Machine learning (ML) models are very sensitive pieces of software; their successful use needs careful monitoring to make sure they are working correctly.
This is especially true when business decisions are made automatically using the outputs of said models. This means that faulty models will very often have a real impact on the end-customer experience.
Models are only as good as the data they consume, so monitoring the input data (and the outputs) is critical for the model to fulfill its real objective: to be useful to drive good decisions and help the business reach its objectives.”
Lessons
Averages don’t tell the full story: Monitoring average values for numerical features can lead to an incomplete picture. Tools often don’t know how to deal with missing (or null data) and assume that data problems will be large enough to move averages significantly. It’s better to monitor percentiles (99th, 95th, 90th, 10th, 5th, 1st, etc) along with missing value rates for all features.
Break monitoring into subpopulations for better insights: It can be easier to understand data by breaking it up into subpopulations that are monitored separately.
Consistency reduces the mental burden of monitoring: Monitoring tools and dashboards should be consistent and standardized. A single tool for monitoring is best with consistent naming of files/datasets/dashboards and these artifacts should be ordered based on priority to end-users.
Patterns for alerting: Real-time alerts (emails, Slack messages) can easily end up being “too noisy” (going off too often and people not taking them seriously) or “not sensitive at all” (not going off even when they should). The authors recommend always including the time frame and specific data points, for example:
“Average value of Feature X in model Y for the past 15 minutes was too high (expected between 0.4 and 0.5, but got 100.0 instead)”
Monitor monitoring jobs/routines themselves (meta-monitoring): Model monitoring tools are just another piece of software and they can stop working from time to time. It’s good to monitor execution times for monitoring jobs and have heartbeat-style alerts.
Conclusion
As the authors say:
“These are a couple of tips we found useful for monitoring several ML models here at Nubank.
They are used in a variety of business contexts (credit, fraud, CX, Operations, etc) and we believe they are general enough to be applicable in other companies too.”
MIT Technology Review | Hundreds of AI tools have been built to catch covid. None of them helped.

A recent article published in MIT Technology Review highlights the challenges of building AI-powered diagnosis and treatment tools for COVID-19, but many of the observations and learnings can be generalized to healthcare.
The Problem
Early in March/April 2020, hospitals around the world scrambled to treat potential COVID-19 cases. In order to help hospitals scale and better allocate resources, many AI efforts were initiated to diagnose the disease. A recent report by Turing Institute in the UK however concluded that AI tools had very little to zero positive impact in helping hospitals fight COVID.
This conclusion is largely in line with a similar one reached by Derek Driggs, a machine-learning researcher at the University of Cambridge. They looked at deep learning models for diagnosing covid from medical images (X-rays, CT scans). Out of the 415 such published tools, they concluded that none were fit for being deployed in clinics (we had covered this briefly here).
What caused it?
In a nutshell, data quality. The article illustrates some failure cases due to data quality and data skew issues that seemed to systematically plague these models. A couple of examples:
Some approaches unknowingly used datasets that contained medical images of children (where the prevalence of COVID is much lower). As a result, the model inadvertently learned to classify kids vs adults
The source of ground truth labels was the doctor’s diagnosis of whether the chest scans showed signs of covid (versus actual ground truth from test results such as PCR). This introduced noise and bias in the data.
What can we learn?
The article summarizes suggestions from healthcare professionals about what we can learn and how to fix this problem:
Transparency and data sharing: Disclosing the source of your data, and if possible releasing the datasets along with the models. While this might not always be possible in healthcare contexts, at the very least sharing the source with doctors and healthcare professionals who intend to use these models in the field can be helpful for them to make informed judgments.
Data standardization: Lack of standardization makes it hard for healthcare data from different sources (hospitals, countries) to be integrated.
Model validation: Validating models from other teams might not be the most glamorous work, but it can help take “tech from ‘lab bench to bedside.’”
Twitter: ML Strategy tip

We love this tweet by Brandon Rohrer. We have both built “very simple models” (read: heuristics) in the past to solve problems, and cannot agree with the sentiment more. As ML practitioners in industry, our job is to create business value -- only sometimes does it require ML!
Thanks
Thanks for making it to the end of the newsletter! This has been curated by Nihit Desai and Rishabh Bhargava. If you have suggestions for what we should be covering in this newsletter, tweet us @mlopsroundup or email us at mlmonitoringnews@gmail.com. If you like what we are doing please tell your friends and colleagues to spread the word.